GPU Clusters#
This document is being ported from here.
Neuropoly has several GPUs available for training deep learning models.
bireli.neuro.polymtl.ca- 2 x GeForce GTX TITAN X (released 2014)rosenberg.neuro.polymtl.ca- 8 x Tesla P100 SXM2 16GB (released 2016)romane.neuro.polymtl.ca- 4 x RTX A6000 (released 2020)tassan.neuro.polymtl.ca- 2 x RTX PRO 6000 Blackwell Max-Q Workstation Edition (released 2025)
Full specs for these stations can be found here.
We have spent money and time on this infrastructure for it to push science forward, so please take advantage of it!
Connecting#
As with other machines, connect with ssh using your GE account.
Hardware#
You can inspect the available GPUs on machine, and their current state, with nvidia-smi:
u918374@rosenberg:~$ nvidia-smi
Fri Jun 4 01:26:14 2021
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 440.33.01 Driver Version: 440.33.01 CUDA Version: 10.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla P100-SXM2... On | 00000000:04:00.0 Off | 0 |
| N/A 25C P0 33W / 300W | 10MiB / 16280MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 1 Tesla P100-SXM2... On | 00000000:05:00.0 Off | 0 |
| N/A 22C P0 33W / 300W | 10MiB / 16280MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 2 Tesla P100-SXM2... On | 00000000:09:00.0 Off | 0 |
| N/A 24C P0 31W / 300W | 10MiB / 16280MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 3 Tesla P100-SXM2... On | 00000000:0A:00.0 Off | 0 |
| N/A 23C P0 31W / 300W | 10MiB / 16280MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 4 Tesla P100-SXM2... On | 00000000:85:00.0 Off | 0 |
| N/A 31C P0 51W / 300W | 10253MiB / 16280MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 5 Tesla P100-SXM2... On | 00000000:86:00.0 Off | 0 |
| N/A 22C P0 41W / 300W | 10253MiB / 16280MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 6 Tesla P100-SXM2... On | 00000000:89:00.0 Off | 0 |
| N/A 32C P0 51W / 300W | 10245MiB / 16280MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 7 Tesla P100-SXM2... On | 00000000:8A:00.0 Off | 0 |
| N/A 38C P0 52W / 300W | 13684MiB / 16280MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 4 32263 C ...L.CA/u12345/venv-ivadomed/bin/python3.6 10243MiB |
| 5 32264 C ...L.CA/u12345/venv-ivadomed/bin/python3.6 10243MiB |
| 6 33062 C ...L.CA/u12345/venv-ivadomed/bin/python3.6 10235MiB |
| 7 33063 C ...L.CA/u12345/venv-ivadomed/bin/python3.6 10235MiB |
| 7 35147 C ...L.CA/u12345/venv-ivadomed/bin/python3.6 3439MiB |
+-----------------------------------------------------------------------------+
Software#
Both tensorflow and torch are included on all of these machines,
or you can install your own versions in a venv or conda environment.
You can check your environemnt is set up right for accessing the GPUs by running nvverify:
nvverify example
root@romane:~# nvverify
======================== GPU Hardware ========================
+ lspci -vvd 10DE:
01:00.0 VGA compatible controller: NVIDIA Corporation GA102GL [RTX A6000] (rev a1) (prog-if 00 [VGA controller])
Subsystem: NVIDIA Corporation GA102GL [RTX A6000]
Control: I/O+ Mem+ BusMaster+ SpecCycle- MemWINV- VGASnoop- ParErr- Stepping- SERR- FastB2B- DisINTx+
Status: Cap+ 66MHz- UDF- FastB2B- ParErr- DEVSEL=fast >TAbort- <TAbort- <MAbort- >SERR- <PERR- INTx-
Latency: 0
Interrupt: pin A routed to IRQ 240
Region 0: Memory at de000000 (32-bit, non-prefetchable) [size=16M]
Region 1: Memory at c0000000 (64-bit, prefetchable) [size=256M]
Region 3: Memory at d0000000 (64-bit, prefetchable) [size=32M]
Region 5: I/O ports at 3000 [size=128]
Expansion ROM at df000000 [virtual] [disabled] [size=512K]
Capabilities: [60] Power Management version 3
Flags: PMEClk- DSI- D1- D2- AuxCurrent=0mA PME(D0+,D1-,D2-,D3hot+,D3cold-)
Status: D0 NoSoftRst+ PME-Enable- DSel=0 DScale=0 PME-
Capabilities: [68] MSI: Enable+ Count=1/1 Maskable- 64bit+
Address: 00000000fee09000 Data: 0023
Capabilities: [78] Express (v2) Legacy Endpoint, MSI 00
DevCap: MaxPayload 256 bytes, PhantFunc 0, Latency L0s unlimited, L1 <64us
ExtTag+ AttnBtn- AttnInd- PwrInd- RBE+ FLReset+
DevCtl: CorrErr+ NonFatalErr+ FatalErr+ UnsupReq-
RlxdOrd+ ExtTag+ PhantFunc- AuxPwr- NoSnoop- FLReset-
MaxPayload 256 bytes, MaxReadReq 512 bytes
DevSta: CorrErr- NonFatalErr- FatalErr- UnsupReq- AuxPwr- TransPend-
LnkCap: Port #0, Speed 16GT/s, Width x16, ASPM L0s L1, Exit Latency L0s <512ns, L1 <4us
ClockPM+ Surprise- LLActRep- BwNot- ASPMOptComp+
LnkCtl: ASPM Disabled; RCB 64 bytes, Disabled- CommClk+
ExtSynch- ClockPM+ AutWidDis- BWInt- AutBWInt-
LnkSta: Speed 2.5GT/s (downgraded), Width x16 (ok)
TrErr- Train- SlotClk+ DLActive- BWMgmt- ABWMgmt-
DevCap2: Completion Timeout: Range AB, TimeoutDis+ NROPrPrP- LTR-
10BitTagComp+ 10BitTagReq+ OBFF Via message, ExtFmt- EETLPPrefix-
EmergencyPowerReduction Not Supported, EmergencyPowerReductionInit-
FRS-
AtomicOpsCap: 32bit- 64bit- 128bitCAS-
DevCtl2: Completion Timeout: 50us to 50ms, TimeoutDis- LTR- OBFF Disabled,
AtomicOpsCtl: ReqEn-
LnkCap2: Supported Link Speeds: 2.5-16GT/s, Crosslink- Retimer+ 2Retimers+ DRS-
LnkCtl2: Target Link Speed: 16GT/s, EnterCompliance- SpeedDis-
Transmit Margin: Normal Operating Range, EnterModifiedCompliance- ComplianceSOS-
Compliance De-emphasis: -6dB
LnkSta2: Current De-emphasis Level: -3.5dB, EqualizationComplete+ EqualizationPhase1+
EqualizationPhase2+ EqualizationPhase3+ LinkEqualizationRequest-
Retimer- 2Retimers- CrosslinkRes: unsupported
Capabilities: [b4] Vendor Specific Information: Len=14 <?>
Capabilities: [100 v1] Virtual Channel
Caps: LPEVC=0 RefClk=100ns PATEntryBits=1
Arb: Fixed- WRR32- WRR64- WRR128-
Ctrl: ArbSelect=Fixed
Status: InProgress-
VC0: Caps: PATOffset=00 MaxTimeSlots=1 RejSnoopTrans-
Arb: Fixed- WRR32- WRR64- WRR128- TWRR128- WRR256-
Ctrl: Enable+ ID=0 ArbSelect=Fixed TC/VC=01
Status: NegoPending- InProgress-
Capabilities: [258 v1] L1 PM Substates
L1SubCap: PCI-PM_L1.2+ PCI-PM_L1.1+ ASPM_L1.2+ ASPM_L1.1+ L1_PM_Substates+
PortCommonModeRestoreTime=255us PortTPowerOnTime=10us
L1SubCtl1: PCI-PM_L1.2- PCI-PM_L1.1- ASPM_L1.2- ASPM_L1.1-
T_CommonMode=0us LTR1.2_Threshold=0ns
L1SubCtl2: T_PwrOn=10us
Capabilities: [128 v1] Power Budgeting <?>
Capabilities: [420 v2] Advanced Error Reporting
UESta: DLP- SDES- TLP- FCP- CmpltTO- CmpltAbrt- UnxCmplt- RxOF- MalfTLP- ECRC- UnsupReq- ACSViol-
UEMsk: DLP- SDES- TLP- FCP- CmpltTO- CmpltAbrt- UnxCmplt- RxOF- MalfTLP- ECRC- UnsupReq+ ACSViol-
UESvrt: DLP+ SDES+ TLP- FCP+ CmpltTO+ CmpltAbrt- UnxCmplt+ RxOF+ MalfTLP+ ECRC- UnsupReq- ACSViol-
CESta: RxErr- BadTLP- BadDLLP- Rollover- Timeout- AdvNonFatalErr-
CEMsk: RxErr- BadTLP- BadDLLP- Rollover- Timeout- AdvNonFatalErr-
AERCap: First Error Pointer: 00, ECRCGenCap- ECRCGenEn- ECRCChkCap- ECRCChkEn-
MultHdrRecCap- MultHdrRecEn- TLPPfxPres- HdrLogCap-
HeaderLog: 00000000 00000000 00000000 00000000
Capabilities: [600 v1] Vendor Specific Information: ID=0001 Rev=1 Len=024 <?>
Capabilities: [900 v1] Secondary PCI Express
LnkCtl3: LnkEquIntrruptEn- PerformEqu-
LaneErrStat: 0
Capabilities: [bb0 v1] Physical Resizable BAR
BAR 0: current size: 16MB, supported: 16MB
BAR 1: current size: 256MB, supported: 64MB 128MB 256MB 512MB 1GB 2GB 4GB 8GB 16GB 32GB 64GB
BAR 3: current size: 32MB, supported: 32MB
Capabilities: [c1c v1] Physical Layer 16.0 GT/s <?>
Capabilities: [d00 v1] Lane Margining at the Receiver <?>
Capabilities: [e00 v1] Data Link Feature <?>
Kernel driver in use: nvidia
Kernel modules: nvidiafb, nouveau, nvidia_drm, nvidia
01:00.1 Audio device: NVIDIA Corporation GA102 High Definition Audio Controller (rev a1)
Subsystem: NVIDIA Corporation GA102 High Definition Audio Controller
Control: I/O- Mem+ BusMaster+ SpecCycle- MemWINV- VGASnoop- ParErr- Stepping- SERR- FastB2B- DisINTx-
Status: Cap+ 66MHz- UDF- FastB2B- ParErr- DEVSEL=fast >TAbort- <TAbort- <MAbort- >SERR- <PERR- INTx-
Latency: 0, Cache Line Size: 64 bytes
Interrupt: pin B routed to IRQ 259
Region 0: Memory at df080000 (32-bit, non-prefetchable) [size=16K]
Capabilities: [60] Power Management version 3
Flags: PMEClk- DSI- D1- D2- AuxCurrent=0mA PME(D0-,D1-,D2-,D3hot-,D3cold-)
Status: D0 NoSoftRst+ PME-Enable- DSel=0 DScale=0 PME-
Capabilities: [68] MSI: Enable- Count=1/1 Maskable- 64bit+
Address: 0000000000000000 Data: 0000
Capabilities: [78] Express (v2) Endpoint, MSI 00
DevCap: MaxPayload 256 bytes, PhantFunc 0, Latency L0s unlimited, L1 <64us
ExtTag+ AttnBtn- AttnInd- PwrInd- RBE+ FLReset- SlotPowerLimit 75.000W
DevCtl: CorrErr+ NonFatalErr+ FatalErr+ UnsupReq-
RlxdOrd+ ExtTag+ PhantFunc- AuxPwr- NoSnoop+
MaxPayload 256 bytes, MaxReadReq 512 bytes
DevSta: CorrErr+ NonFatalErr- FatalErr- UnsupReq+ AuxPwr- TransPend-
LnkCap: Port #0, Speed 16GT/s, Width x16, ASPM L0s L1, Exit Latency L0s <512ns, L1 <4us
ClockPM+ Surprise- LLActRep- BwNot- ASPMOptComp+
LnkCtl: ASPM Disabled; RCB 64 bytes, Disabled- CommClk+
ExtSynch- ClockPM- AutWidDis- BWInt- AutBWInt-
LnkSta: Speed 2.5GT/s (downgraded), Width x16 (ok)
TrErr- Train- SlotClk+ DLActive- BWMgmt- ABWMgmt-
DevCap2: Completion Timeout: Range AB, TimeoutDis+ NROPrPrP- LTR-
10BitTagComp+ 10BitTagReq+ OBFF Via message, ExtFmt- EETLPPrefix-
EmergencyPowerReduction Not Supported, EmergencyPowerReductionInit-
FRS- TPHComp- ExtTPHComp-
AtomicOpsCap: 32bit- 64bit- 128bitCAS-
DevCtl2: Completion Timeout: 50us to 50ms, TimeoutDis- LTR- OBFF Disabled,
AtomicOpsCtl: ReqEn-
LnkSta2: Current De-emphasis Level: -3.5dB, EqualizationComplete- EqualizationPhase1-
EqualizationPhase2- EqualizationPhase3- LinkEqualizationRequest-
Retimer- 2Retimers- CrosslinkRes: unsupported
Capabilities: [100 v2] Advanced Error Reporting
UESta: DLP- SDES- TLP- FCP- CmpltTO- CmpltAbrt- UnxCmplt- RxOF- MalfTLP- ECRC- UnsupReq+ ACSViol-
UEMsk: DLP- SDES- TLP- FCP- CmpltTO- CmpltAbrt- UnxCmplt- RxOF- MalfTLP- ECRC- UnsupReq+ ACSViol-
UESvrt: DLP+ SDES+ TLP- FCP+ CmpltTO+ CmpltAbrt- UnxCmplt+ RxOF+ MalfTLP+ ECRC- UnsupReq- ACSViol-
CESta: RxErr- BadTLP- BadDLLP- Rollover- Timeout- AdvNonFatalErr+
CEMsk: RxErr- BadTLP- BadDLLP- Rollover- Timeout- AdvNonFatalErr-
AERCap: First Error Pointer: 00, ECRCGenCap- ECRCGenEn- ECRCChkCap- ECRCChkEn-
MultHdrRecCap- MultHdrRecEn- TLPPfxPres- HdrLogCap-
HeaderLog: 00000000 00000000 00000000 00000000
Capabilities: [160 v1] Data Link Feature <?>
Kernel driver in use: snd_hda_intel
Kernel modules: snd_hda_intel
41:00.0 VGA compatible controller: NVIDIA Corporation GA102GL [RTX A6000] (rev a1) (prog-if 00 [VGA controller])
Subsystem: NVIDIA Corporation GA102GL [RTX A6000]
Control: I/O+ Mem+ BusMaster+ SpecCycle- MemWINV- VGASnoop- ParErr- Stepping- SERR- FastB2B- DisINTx+
Status: Cap+ 66MHz- UDF- FastB2B- ParErr- DEVSEL=fast >TAbort- <TAbort- <MAbort- >SERR- <PERR- INTx-
Latency: 0
Interrupt: pin A routed to IRQ 239
Region 0: Memory at b0000000 (32-bit, non-prefetchable) [size=16M]
Region 1: Memory at 28060000000 (64-bit, prefetchable) [size=256M]
Region 3: Memory at 28070000000 (64-bit, prefetchable) [size=32M]
Region 5: I/O ports at 7000 [size=128]
Expansion ROM at b1000000 [virtual] [disabled] [size=512K]
Capabilities: [60] Power Management version 3
Flags: PMEClk- DSI- D1- D2- AuxCurrent=0mA PME(D0+,D1-,D2-,D3hot+,D3cold-)
Status: D0 NoSoftRst+ PME-Enable- DSel=0 DScale=0 PME-
Capabilities: [68] MSI: Enable+ Count=1/1 Maskable- 64bit+
Address: 00000000fee1d000 Data: 0023
Capabilities: [78] Express (v2) Legacy Endpoint, MSI 00
DevCap: MaxPayload 256 bytes, PhantFunc 0, Latency L0s unlimited, L1 <64us
ExtTag+ AttnBtn- AttnInd- PwrInd- RBE+ FLReset+
DevCtl: CorrErr+ NonFatalErr+ FatalErr+ UnsupReq-
RlxdOrd+ ExtTag+ PhantFunc- AuxPwr- NoSnoop- FLReset-
MaxPayload 256 bytes, MaxReadReq 512 bytes
DevSta: CorrErr- NonFatalErr- FatalErr- UnsupReq- AuxPwr- TransPend-
LnkCap: Port #0, Speed 16GT/s, Width x16, ASPM L0s L1, Exit Latency L0s <512ns, L1 <4us
ClockPM+ Surprise- LLActRep- BwNot- ASPMOptComp+
LnkCtl: ASPM Disabled; RCB 64 bytes, Disabled- CommClk+
ExtSynch- ClockPM+ AutWidDis- BWInt- AutBWInt-
LnkSta: Speed 2.5GT/s (downgraded), Width x16 (ok)
TrErr- Train- SlotClk+ DLActive- BWMgmt- ABWMgmt-
DevCap2: Completion Timeout: Range AB, TimeoutDis+ NROPrPrP- LTR-
10BitTagComp+ 10BitTagReq+ OBFF Via message, ExtFmt- EETLPPrefix-
EmergencyPowerReduction Not Supported, EmergencyPowerReductionInit-
FRS-
AtomicOpsCap: 32bit- 64bit- 128bitCAS-
DevCtl2: Completion Timeout: 50us to 50ms, TimeoutDis- LTR- OBFF Disabled,
AtomicOpsCtl: ReqEn-
LnkCap2: Supported Link Speeds: 2.5-16GT/s, Crosslink- Retimer+ 2Retimers+ DRS-
LnkCtl2: Target Link Speed: 16GT/s, EnterCompliance- SpeedDis-
Transmit Margin: Normal Operating Range, EnterModifiedCompliance- ComplianceSOS-
Compliance De-emphasis: -6dB
LnkSta2: Current De-emphasis Level: -3.5dB, EqualizationComplete+ EqualizationPhase1+
EqualizationPhase2+ EqualizationPhase3+ LinkEqualizationRequest-
Retimer- 2Retimers- CrosslinkRes: unsupported
Capabilities: [b4] Vendor Specific Information: Len=14 <?>
Capabilities: [100 v1] Virtual Channel
Caps: LPEVC=0 RefClk=100ns PATEntryBits=1
Arb: Fixed- WRR32- WRR64- WRR128-
Ctrl: ArbSelect=Fixed
Status: InProgress-
VC0: Caps: PATOffset=00 MaxTimeSlots=1 RejSnoopTrans-
Arb: Fixed- WRR32- WRR64- WRR128- TWRR128- WRR256-
Ctrl: Enable+ ID=0 ArbSelect=Fixed TC/VC=01
Status: NegoPending- InProgress-
Capabilities: [258 v1] L1 PM Substates
L1SubCap: PCI-PM_L1.2+ PCI-PM_L1.1+ ASPM_L1.2+ ASPM_L1.1+ L1_PM_Substates+
PortCommonModeRestoreTime=255us PortTPowerOnTime=10us
L1SubCtl1: PCI-PM_L1.2- PCI-PM_L1.1- ASPM_L1.2- ASPM_L1.1-
T_CommonMode=0us LTR1.2_Threshold=0ns
L1SubCtl2: T_PwrOn=10us
Capabilities: [128 v1] Power Budgeting <?>
Capabilities: [420 v2] Advanced Error Reporting
UESta: DLP- SDES- TLP- FCP- CmpltTO- CmpltAbrt- UnxCmplt- RxOF- MalfTLP- ECRC- UnsupReq- ACSViol-
UEMsk: DLP- SDES- TLP- FCP- CmpltTO- CmpltAbrt- UnxCmplt- RxOF- MalfTLP- ECRC- UnsupReq+ ACSViol-
UESvrt: DLP+ SDES+ TLP- FCP+ CmpltTO+ CmpltAbrt- UnxCmplt+ RxOF+ MalfTLP+ ECRC- UnsupReq- ACSViol-
CESta: RxErr- BadTLP- BadDLLP- Rollover- Timeout- AdvNonFatalErr-
CEMsk: RxErr- BadTLP- BadDLLP- Rollover- Timeout- AdvNonFatalErr-
AERCap: First Error Pointer: 00, ECRCGenCap- ECRCGenEn- ECRCChkCap- ECRCChkEn-
MultHdrRecCap- MultHdrRecEn- TLPPfxPres- HdrLogCap-
HeaderLog: 00000000 00000000 00000000 00000000
Capabilities: [600 v1] Vendor Specific Information: ID=0001 Rev=1 Len=024 <?>
Capabilities: [900 v1] Secondary PCI Express
LnkCtl3: LnkEquIntrruptEn- PerformEqu-
LaneErrStat: 0
Capabilities: [bb0 v1] Physical Resizable BAR
BAR 0: current size: 16MB, supported: 16MB
BAR 1: current size: 256MB, supported: 64MB 128MB 256MB 512MB 1GB 2GB 4GB 8GB 16GB 32GB 64GB
BAR 3: current size: 32MB, supported: 32MB
Capabilities: [c1c v1] Physical Layer 16.0 GT/s <?>
Capabilities: [d00 v1] Lane Margining at the Receiver <?>
Capabilities: [e00 v1] Data Link Feature <?>
Kernel driver in use: nvidia
Kernel modules: nvidiafb, nouveau, nvidia_drm, nvidia
41:00.1 Audio device: NVIDIA Corporation GA102 High Definition Audio Controller (rev a1)
Subsystem: NVIDIA Corporation GA102 High Definition Audio Controller
Control: I/O- Mem+ BusMaster+ SpecCycle- MemWINV- VGASnoop- ParErr- Stepping- SERR- FastB2B- DisINTx-
Status: Cap+ 66MHz- UDF- FastB2B- ParErr- DEVSEL=fast >TAbort- <TAbort- <MAbort- >SERR- <PERR- INTx-
Latency: 0, Cache Line Size: 64 bytes
Interrupt: pin B routed to IRQ 258
Region 0: Memory at b1080000 (32-bit, non-prefetchable) [size=16K]
Capabilities: [60] Power Management version 3
Flags: PMEClk- DSI- D1- D2- AuxCurrent=0mA PME(D0-,D1-,D2-,D3hot-,D3cold-)
Status: D0 NoSoftRst+ PME-Enable- DSel=0 DScale=0 PME-
Capabilities: [68] MSI: Enable- Count=1/1 Maskable- 64bit+
Address: 0000000000000000 Data: 0000
Capabilities: [78] Express (v2) Endpoint, MSI 00
DevCap: MaxPayload 256 bytes, PhantFunc 0, Latency L0s unlimited, L1 <64us
ExtTag+ AttnBtn- AttnInd- PwrInd- RBE+ FLReset- SlotPowerLimit 75.000W
DevCtl: CorrErr+ NonFatalErr+ FatalErr+ UnsupReq-
RlxdOrd+ ExtTag+ PhantFunc- AuxPwr- NoSnoop+
MaxPayload 256 bytes, MaxReadReq 512 bytes
DevSta: CorrErr+ NonFatalErr- FatalErr- UnsupReq+ AuxPwr- TransPend-
LnkCap: Port #0, Speed 16GT/s, Width x16, ASPM L0s L1, Exit Latency L0s <512ns, L1 <4us
ClockPM+ Surprise- LLActRep- BwNot- ASPMOptComp+
LnkCtl: ASPM Disabled; RCB 64 bytes, Disabled- CommClk+
ExtSynch- ClockPM- AutWidDis- BWInt- AutBWInt-
LnkSta: Speed 2.5GT/s (downgraded), Width x16 (ok)
TrErr- Train- SlotClk+ DLActive- BWMgmt- ABWMgmt-
DevCap2: Completion Timeout: Range AB, TimeoutDis+ NROPrPrP- LTR-
10BitTagComp+ 10BitTagReq+ OBFF Via message, ExtFmt- EETLPPrefix-
EmergencyPowerReduction Not Supported, EmergencyPowerReductionInit-
FRS- TPHComp- ExtTPHComp-
AtomicOpsCap: 32bit- 64bit- 128bitCAS-
DevCtl2: Completion Timeout: 50us to 50ms, TimeoutDis- LTR- OBFF Disabled,
AtomicOpsCtl: ReqEn-
LnkSta2: Current De-emphasis Level: -3.5dB, EqualizationComplete- EqualizationPhase1-
EqualizationPhase2- EqualizationPhase3- LinkEqualizationRequest-
Retimer- 2Retimers- CrosslinkRes: unsupported
Capabilities: [100 v2] Advanced Error Reporting
UESta: DLP- SDES- TLP- FCP- CmpltTO- CmpltAbrt- UnxCmplt- RxOF- MalfTLP- ECRC- UnsupReq+ ACSViol-
UEMsk: DLP- SDES- TLP- FCP- CmpltTO- CmpltAbrt- UnxCmplt- RxOF- MalfTLP- ECRC- UnsupReq+ ACSViol-
UESvrt: DLP+ SDES+ TLP- FCP+ CmpltTO+ CmpltAbrt- UnxCmplt+ RxOF+ MalfTLP+ ECRC- UnsupReq- ACSViol-
CESta: RxErr- BadTLP- BadDLLP- Rollover- Timeout- AdvNonFatalErr+
CEMsk: RxErr- BadTLP- BadDLLP- Rollover- Timeout- AdvNonFatalErr-
AERCap: First Error Pointer: 00, ECRCGenCap- ECRCGenEn- ECRCChkCap- ECRCChkEn-
MultHdrRecCap- MultHdrRecEn- TLPPfxPres- HdrLogCap-
HeaderLog: 00000000 00000000 00000000 00000000
Capabilities: [160 v1] Data Link Feature <?>
Kernel driver in use: snd_hda_intel
Kernel modules: snd_hda_intel
81:00.0 VGA compatible controller: NVIDIA Corporation GA102GL [RTX A6000] (rev a1) (prog-if 00 [VGA controller])
Subsystem: NVIDIA Corporation GA102GL [RTX A6000]
Control: I/O+ Mem+ BusMaster+ SpecCycle- MemWINV- VGASnoop- ParErr- Stepping- SERR- FastB2B- DisINTx+
Status: Cap+ 66MHz- UDF- FastB2B- ParErr- DEVSEL=fast >TAbort- <TAbort- <MAbort- >SERR- <PERR- INTx-
Latency: 0
Interrupt: pin A routed to IRQ 238
Region 0: Memory at f0000000 (32-bit, non-prefetchable) [size=16M]
Region 1: Memory at 20030000000 (64-bit, prefetchable) [size=256M]
Region 3: Memory at 20040000000 (64-bit, prefetchable) [size=32M]
Region 5: I/O ports at b000 [size=128]
Expansion ROM at f1000000 [virtual] [disabled] [size=512K]
Capabilities: [60] Power Management version 3
Flags: PMEClk- DSI- D1- D2- AuxCurrent=0mA PME(D0+,D1-,D2-,D3hot+,D3cold-)
Status: D0 NoSoftRst+ PME-Enable- DSel=0 DScale=0 PME-
Capabilities: [68] MSI: Enable+ Count=1/1 Maskable- 64bit+
Address: 00000000fee24000 Data: 0023
Capabilities: [78] Express (v2) Legacy Endpoint, MSI 00
DevCap: MaxPayload 256 bytes, PhantFunc 0, Latency L0s unlimited, L1 <64us
ExtTag+ AttnBtn- AttnInd- PwrInd- RBE+ FLReset+
DevCtl: CorrErr+ NonFatalErr+ FatalErr+ UnsupReq-
RlxdOrd+ ExtTag+ PhantFunc- AuxPwr- NoSnoop- FLReset-
MaxPayload 256 bytes, MaxReadReq 512 bytes
DevSta: CorrErr- NonFatalErr- FatalErr- UnsupReq- AuxPwr- TransPend-
LnkCap: Port #0, Speed 16GT/s, Width x16, ASPM L0s L1, Exit Latency L0s <512ns, L1 <4us
ClockPM+ Surprise- LLActRep- BwNot- ASPMOptComp+
LnkCtl: ASPM Disabled; RCB 64 bytes, Disabled- CommClk+
ExtSynch- ClockPM+ AutWidDis- BWInt- AutBWInt-
LnkSta: Speed 2.5GT/s (downgraded), Width x16 (ok)
TrErr- Train- SlotClk+ DLActive- BWMgmt- ABWMgmt-
DevCap2: Completion Timeout: Range AB, TimeoutDis+ NROPrPrP- LTR-
10BitTagComp+ 10BitTagReq+ OBFF Via message, ExtFmt- EETLPPrefix-
EmergencyPowerReduction Not Supported, EmergencyPowerReductionInit-
FRS-
AtomicOpsCap: 32bit- 64bit- 128bitCAS-
DevCtl2: Completion Timeout: 50us to 50ms, TimeoutDis- LTR- OBFF Disabled,
AtomicOpsCtl: ReqEn-
LnkCap2: Supported Link Speeds: 2.5-16GT/s, Crosslink- Retimer+ 2Retimers+ DRS-
LnkCtl2: Target Link Speed: 16GT/s, EnterCompliance- SpeedDis-
Transmit Margin: Normal Operating Range, EnterModifiedCompliance- ComplianceSOS-
Compliance De-emphasis: -6dB
LnkSta2: Current De-emphasis Level: -3.5dB, EqualizationComplete+ EqualizationPhase1+
EqualizationPhase2+ EqualizationPhase3+ LinkEqualizationRequest-
Retimer- 2Retimers- CrosslinkRes: unsupported
Capabilities: [b4] Vendor Specific Information: Len=14 <?>
Capabilities: [100 v1] Virtual Channel
Caps: LPEVC=0 RefClk=100ns PATEntryBits=1
Arb: Fixed- WRR32- WRR64- WRR128-
Ctrl: ArbSelect=Fixed
Status: InProgress-
VC0: Caps: PATOffset=00 MaxTimeSlots=1 RejSnoopTrans-
Arb: Fixed- WRR32- WRR64- WRR128- TWRR128- WRR256-
Ctrl: Enable+ ID=0 ArbSelect=Fixed TC/VC=01
Status: NegoPending- InProgress-
Capabilities: [258 v1] L1 PM Substates
L1SubCap: PCI-PM_L1.2+ PCI-PM_L1.1+ ASPM_L1.2+ ASPM_L1.1+ L1_PM_Substates+
PortCommonModeRestoreTime=255us PortTPowerOnTime=10us
L1SubCtl1: PCI-PM_L1.2- PCI-PM_L1.1- ASPM_L1.2- ASPM_L1.1-
T_CommonMode=0us LTR1.2_Threshold=0ns
L1SubCtl2: T_PwrOn=10us
Capabilities: [128 v1] Power Budgeting <?>
Capabilities: [420 v2] Advanced Error Reporting
UESta: DLP- SDES- TLP- FCP- CmpltTO- CmpltAbrt- UnxCmplt- RxOF- MalfTLP- ECRC- UnsupReq- ACSViol-
UEMsk: DLP- SDES- TLP- FCP- CmpltTO- CmpltAbrt- UnxCmplt- RxOF- MalfTLP- ECRC- UnsupReq+ ACSViol-
UESvrt: DLP+ SDES+ TLP- FCP+ CmpltTO+ CmpltAbrt- UnxCmplt+ RxOF+ MalfTLP+ ECRC- UnsupReq- ACSViol-
CESta: RxErr- BadTLP- BadDLLP- Rollover- Timeout- AdvNonFatalErr-
CEMsk: RxErr- BadTLP- BadDLLP- Rollover- Timeout- AdvNonFatalErr-
AERCap: First Error Pointer: 00, ECRCGenCap- ECRCGenEn- ECRCChkCap- ECRCChkEn-
MultHdrRecCap- MultHdrRecEn- TLPPfxPres- HdrLogCap-
HeaderLog: 00000000 00000000 00000000 00000000
Capabilities: [600 v1] Vendor Specific Information: ID=0001 Rev=1 Len=024 <?>
Capabilities: [900 v1] Secondary PCI Express
LnkCtl3: LnkEquIntrruptEn- PerformEqu-
LaneErrStat: 0
Capabilities: [bb0 v1] Physical Resizable BAR
BAR 0: current size: 16MB, supported: 16MB
BAR 1: current size: 256MB, supported: 64MB 128MB 256MB 512MB 1GB 2GB 4GB 8GB 16GB 32GB 64GB
BAR 3: current size: 32MB, supported: 32MB
Capabilities: [c1c v1] Physical Layer 16.0 GT/s <?>
Capabilities: [d00 v1] Lane Margining at the Receiver <?>
Capabilities: [e00 v1] Data Link Feature <?>
Kernel driver in use: nvidia
Kernel modules: nvidiafb, nouveau, nvidia_drm, nvidia
81:00.1 Audio device: NVIDIA Corporation GA102 High Definition Audio Controller (rev a1)
Subsystem: NVIDIA Corporation GA102 High Definition Audio Controller
Control: I/O- Mem+ BusMaster+ SpecCycle- MemWINV- VGASnoop- ParErr- Stepping- SERR- FastB2B- DisINTx-
Status: Cap+ 66MHz- UDF- FastB2B- ParErr- DEVSEL=fast >TAbort- <TAbort- <MAbort- >SERR- <PERR- INTx-
Latency: 0, Cache Line Size: 64 bytes
Interrupt: pin B routed to IRQ 257
Region 0: Memory at f1080000 (32-bit, non-prefetchable) [size=16K]
Capabilities: [60] Power Management version 3
Flags: PMEClk- DSI- D1- D2- AuxCurrent=0mA PME(D0-,D1-,D2-,D3hot-,D3cold-)
Status: D0 NoSoftRst+ PME-Enable- DSel=0 DScale=0 PME-
Capabilities: [68] MSI: Enable- Count=1/1 Maskable- 64bit+
Address: 0000000000000000 Data: 0000
Capabilities: [78] Express (v2) Endpoint, MSI 00
DevCap: MaxPayload 256 bytes, PhantFunc 0, Latency L0s unlimited, L1 <64us
ExtTag+ AttnBtn- AttnInd- PwrInd- RBE+ FLReset- SlotPowerLimit 75.000W
DevCtl: CorrErr+ NonFatalErr+ FatalErr+ UnsupReq-
RlxdOrd+ ExtTag+ PhantFunc- AuxPwr- NoSnoop+
MaxPayload 256 bytes, MaxReadReq 512 bytes
DevSta: CorrErr+ NonFatalErr- FatalErr- UnsupReq+ AuxPwr- TransPend-
LnkCap: Port #0, Speed 16GT/s, Width x16, ASPM L0s L1, Exit Latency L0s <512ns, L1 <4us
ClockPM+ Surprise- LLActRep- BwNot- ASPMOptComp+
LnkCtl: ASPM Disabled; RCB 64 bytes, Disabled- CommClk+
ExtSynch- ClockPM- AutWidDis- BWInt- AutBWInt-
LnkSta: Speed 2.5GT/s (downgraded), Width x16 (ok)
TrErr- Train- SlotClk+ DLActive- BWMgmt- ABWMgmt-
DevCap2: Completion Timeout: Range AB, TimeoutDis+ NROPrPrP- LTR-
10BitTagComp+ 10BitTagReq+ OBFF Via message, ExtFmt- EETLPPrefix-
EmergencyPowerReduction Not Supported, EmergencyPowerReductionInit-
FRS- TPHComp- ExtTPHComp-
AtomicOpsCap: 32bit- 64bit- 128bitCAS-
DevCtl2: Completion Timeout: 50us to 50ms, TimeoutDis- LTR- OBFF Disabled,
AtomicOpsCtl: ReqEn-
LnkSta2: Current De-emphasis Level: -3.5dB, EqualizationComplete- EqualizationPhase1-
EqualizationPhase2- EqualizationPhase3- LinkEqualizationRequest-
Retimer- 2Retimers- CrosslinkRes: unsupported
Capabilities: [100 v2] Advanced Error Reporting
UESta: DLP- SDES- TLP- FCP- CmpltTO- CmpltAbrt- UnxCmplt- RxOF- MalfTLP- ECRC- UnsupReq+ ACSViol-
UEMsk: DLP- SDES- TLP- FCP- CmpltTO- CmpltAbrt- UnxCmplt- RxOF- MalfTLP- ECRC- UnsupReq+ ACSViol-
UESvrt: DLP+ SDES+ TLP- FCP+ CmpltTO+ CmpltAbrt- UnxCmplt+ RxOF+ MalfTLP+ ECRC- UnsupReq- ACSViol-
CESta: RxErr- BadTLP- BadDLLP- Rollover- Timeout- AdvNonFatalErr+
CEMsk: RxErr- BadTLP- BadDLLP- Rollover- Timeout- AdvNonFatalErr-
AERCap: First Error Pointer: 00, ECRCGenCap- ECRCGenEn- ECRCChkCap- ECRCChkEn-
MultHdrRecCap- MultHdrRecEn- TLPPfxPres- HdrLogCap-
HeaderLog: 00000000 00000000 00000000 00000000
Capabilities: [160 v1] Data Link Feature <?>
Kernel driver in use: snd_hda_intel
Kernel modules: snd_hda_intel
c1:00.0 VGA compatible controller: NVIDIA Corporation GA102GL [RTX A6000] (rev a1) (prog-if 00 [VGA controller])
Subsystem: NVIDIA Corporation GA102GL [RTX A6000]
Control: I/O+ Mem+ BusMaster+ SpecCycle- MemWINV- VGASnoop- ParErr- Stepping- SERR- FastB2B- DisINTx+
Status: Cap+ 66MHz- UDF- FastB2B- ParErr- DEVSEL=fast >TAbort- <TAbort- <MAbort- >SERR- <PERR- INTx-
Latency: 0
Interrupt: pin A routed to IRQ 173
Region 0: Memory at f9000000 (32-bit, non-prefetchable) [size=16M]
Region 1: Memory at 18000000000 (64-bit, prefetchable) [size=256M]
Region 3: Memory at 18010000000 (64-bit, prefetchable) [size=32M]
Region 5: I/O ports at f000 [size=128]
Expansion ROM at fa000000 [virtual] [disabled] [size=512K]
Capabilities: [60] Power Management version 3
Flags: PMEClk- DSI- D1- D2- AuxCurrent=0mA PME(D0+,D1-,D2-,D3hot+,D3cold-)
Status: D0 NoSoftRst+ PME-Enable- DSel=0 DScale=0 PME-
Capabilities: [68] MSI: Enable+ Count=1/1 Maskable- 64bit+
Address: 00000000fee0a000 Data: 0023
Capabilities: [78] Express (v2) Legacy Endpoint, MSI 00
DevCap: MaxPayload 256 bytes, PhantFunc 0, Latency L0s unlimited, L1 <64us
ExtTag+ AttnBtn- AttnInd- PwrInd- RBE+ FLReset+
DevCtl: CorrErr+ NonFatalErr+ FatalErr+ UnsupReq-
RlxdOrd+ ExtTag+ PhantFunc- AuxPwr- NoSnoop- FLReset-
MaxPayload 256 bytes, MaxReadReq 512 bytes
DevSta: CorrErr- NonFatalErr- FatalErr- UnsupReq- AuxPwr- TransPend-
LnkCap: Port #0, Speed 16GT/s, Width x16, ASPM L0s L1, Exit Latency L0s <512ns, L1 <4us
ClockPM+ Surprise- LLActRep- BwNot- ASPMOptComp+
LnkCtl: ASPM Disabled; RCB 64 bytes, Disabled- CommClk+
ExtSynch- ClockPM+ AutWidDis- BWInt- AutBWInt-
LnkSta: Speed 2.5GT/s (downgraded), Width x16 (ok)
TrErr- Train- SlotClk+ DLActive- BWMgmt- ABWMgmt-
DevCap2: Completion Timeout: Range AB, TimeoutDis+ NROPrPrP- LTR-
10BitTagComp+ 10BitTagReq+ OBFF Via message, ExtFmt- EETLPPrefix-
EmergencyPowerReduction Not Supported, EmergencyPowerReductionInit-
FRS-
AtomicOpsCap: 32bit- 64bit- 128bitCAS-
DevCtl2: Completion Timeout: 50us to 50ms, TimeoutDis- LTR- OBFF Disabled,
AtomicOpsCtl: ReqEn-
LnkCap2: Supported Link Speeds: 2.5-16GT/s, Crosslink- Retimer+ 2Retimers+ DRS-
LnkCtl2: Target Link Speed: 16GT/s, EnterCompliance- SpeedDis-
Transmit Margin: Normal Operating Range, EnterModifiedCompliance- ComplianceSOS-
Compliance De-emphasis: -6dB
LnkSta2: Current De-emphasis Level: -3.5dB, EqualizationComplete+ EqualizationPhase1+
EqualizationPhase2+ EqualizationPhase3+ LinkEqualizationRequest-
Retimer- 2Retimers- CrosslinkRes: unsupported
Capabilities: [b4] Vendor Specific Information: Len=14 <?>
Capabilities: [100 v1] Virtual Channel
Caps: LPEVC=0 RefClk=100ns PATEntryBits=1
Arb: Fixed- WRR32- WRR64- WRR128-
Ctrl: ArbSelect=Fixed
Status: InProgress-
VC0: Caps: PATOffset=00 MaxTimeSlots=1 RejSnoopTrans-
Arb: Fixed- WRR32- WRR64- WRR128- TWRR128- WRR256-
Ctrl: Enable+ ID=0 ArbSelect=Fixed TC/VC=01
Status: NegoPending- InProgress-
Capabilities: [258 v1] L1 PM Substates
L1SubCap: PCI-PM_L1.2+ PCI-PM_L1.1+ ASPM_L1.2+ ASPM_L1.1+ L1_PM_Substates+
PortCommonModeRestoreTime=255us PortTPowerOnTime=10us
L1SubCtl1: PCI-PM_L1.2- PCI-PM_L1.1- ASPM_L1.2- ASPM_L1.1-
T_CommonMode=0us LTR1.2_Threshold=0ns
L1SubCtl2: T_PwrOn=10us
Capabilities: [128 v1] Power Budgeting <?>
Capabilities: [420 v2] Advanced Error Reporting
UESta: DLP- SDES- TLP- FCP- CmpltTO- CmpltAbrt- UnxCmplt- RxOF- MalfTLP- ECRC- UnsupReq- ACSViol-
UEMsk: DLP- SDES- TLP- FCP- CmpltTO- CmpltAbrt- UnxCmplt- RxOF- MalfTLP- ECRC- UnsupReq+ ACSViol-
UESvrt: DLP+ SDES+ TLP- FCP+ CmpltTO+ CmpltAbrt- UnxCmplt+ RxOF+ MalfTLP+ ECRC- UnsupReq- ACSViol-
CESta: RxErr- BadTLP- BadDLLP- Rollover- Timeout- AdvNonFatalErr-
CEMsk: RxErr- BadTLP- BadDLLP- Rollover- Timeout- AdvNonFatalErr-
AERCap: First Error Pointer: 00, ECRCGenCap- ECRCGenEn- ECRCChkCap- ECRCChkEn-
MultHdrRecCap- MultHdrRecEn- TLPPfxPres- HdrLogCap-
HeaderLog: 00000000 00000000 00000000 00000000
Capabilities: [600 v1] Vendor Specific Information: ID=0001 Rev=1 Len=024 <?>
Capabilities: [900 v1] Secondary PCI Express
LnkCtl3: LnkEquIntrruptEn- PerformEqu-
LaneErrStat: 0
Capabilities: [bb0 v1] Physical Resizable BAR
BAR 0: current size: 16MB, supported: 16MB
BAR 1: current size: 256MB, supported: 64MB 128MB 256MB 512MB 1GB 2GB 4GB 8GB 16GB 32GB 64GB
BAR 3: current size: 32MB, supported: 32MB
Capabilities: [c1c v1] Physical Layer 16.0 GT/s <?>
Capabilities: [d00 v1] Lane Margining at the Receiver <?>
Capabilities: [e00 v1] Data Link Feature <?>
Kernel driver in use: nvidia
Kernel modules: nvidiafb, nouveau, nvidia_drm, nvidia
c1:00.1 Audio device: NVIDIA Corporation GA102 High Definition Audio Controller (rev a1)
Subsystem: NVIDIA Corporation GA102 High Definition Audio Controller
Control: I/O- Mem+ BusMaster+ SpecCycle- MemWINV- VGASnoop- ParErr- Stepping- SERR- FastB2B- DisINTx-
Status: Cap+ 66MHz- UDF- FastB2B- ParErr- DEVSEL=fast >TAbort- <TAbort- <MAbort- >SERR- <PERR- INTx-
Latency: 0, Cache Line Size: 64 bytes
Interrupt: pin B routed to IRQ 256
Region 0: Memory at fa080000 (32-bit, non-prefetchable) [size=16K]
Capabilities: [60] Power Management version 3
Flags: PMEClk- DSI- D1- D2- AuxCurrent=0mA PME(D0-,D1-,D2-,D3hot-,D3cold-)
Status: D0 NoSoftRst+ PME-Enable- DSel=0 DScale=0 PME-
Capabilities: [68] MSI: Enable- Count=1/1 Maskable- 64bit+
Address: 0000000000000000 Data: 0000
Capabilities: [78] Express (v2) Endpoint, MSI 00
DevCap: MaxPayload 256 bytes, PhantFunc 0, Latency L0s unlimited, L1 <64us
ExtTag+ AttnBtn- AttnInd- PwrInd- RBE+ FLReset- SlotPowerLimit 75.000W
DevCtl: CorrErr+ NonFatalErr+ FatalErr+ UnsupReq-
RlxdOrd+ ExtTag+ PhantFunc- AuxPwr- NoSnoop+
MaxPayload 256 bytes, MaxReadReq 512 bytes
DevSta: CorrErr+ NonFatalErr- FatalErr- UnsupReq+ AuxPwr- TransPend-
LnkCap: Port #0, Speed 16GT/s, Width x16, ASPM L0s L1, Exit Latency L0s <512ns, L1 <4us
ClockPM+ Surprise- LLActRep- BwNot- ASPMOptComp+
LnkCtl: ASPM Disabled; RCB 64 bytes, Disabled- CommClk+
ExtSynch- ClockPM- AutWidDis- BWInt- AutBWInt-
LnkSta: Speed 2.5GT/s (downgraded), Width x16 (ok)
TrErr- Train- SlotClk+ DLActive- BWMgmt- ABWMgmt-
DevCap2: Completion Timeout: Range AB, TimeoutDis+ NROPrPrP- LTR-
10BitTagComp+ 10BitTagReq+ OBFF Via message, ExtFmt- EETLPPrefix-
EmergencyPowerReduction Not Supported, EmergencyPowerReductionInit-
FRS- TPHComp- ExtTPHComp-
AtomicOpsCap: 32bit- 64bit- 128bitCAS-
DevCtl2: Completion Timeout: 50us to 50ms, TimeoutDis- LTR- OBFF Disabled,
AtomicOpsCtl: ReqEn-
LnkSta2: Current De-emphasis Level: -3.5dB, EqualizationComplete- EqualizationPhase1-
EqualizationPhase2- EqualizationPhase3- LinkEqualizationRequest-
Retimer- 2Retimers- CrosslinkRes: unsupported
Capabilities: [100 v2] Advanced Error Reporting
UESta: DLP- SDES- TLP- FCP- CmpltTO- CmpltAbrt- UnxCmplt- RxOF- MalfTLP- ECRC- UnsupReq+ ACSViol-
UEMsk: DLP- SDES- TLP- FCP- CmpltTO- CmpltAbrt- UnxCmplt- RxOF- MalfTLP- ECRC- UnsupReq+ ACSViol-
UESvrt: DLP+ SDES+ TLP- FCP+ CmpltTO+ CmpltAbrt- UnxCmplt+ RxOF+ MalfTLP+ ECRC- UnsupReq- ACSViol-
CESta: RxErr- BadTLP- BadDLLP- Rollover- Timeout- AdvNonFatalErr+
CEMsk: RxErr- BadTLP- BadDLLP- Rollover- Timeout- AdvNonFatalErr-
AERCap: First Error Pointer: 00, ECRCGenCap- ECRCGenEn- ECRCChkCap- ECRCChkEn-
MultHdrRecCap- MultHdrRecEn- TLPPfxPres- HdrLogCap-
HeaderLog: 00000000 00000000 00000000 00000000
Capabilities: [160 v1] Data Link Feature <?>
Kernel driver in use: snd_hda_intel
Kernel modules: snd_hda_intel
======================== GPU Driver ========================
+ cat /sys/module/nvidia/version
510.73.05
+ modinfo nvidia
filename: /lib/modules/5.15.0-30-generic/updates/dkms/nvidia.ko
firmware: nvidia/510.73.05/gsp.bin
alias: char-major-195-*
version: 510.73.05
supported: external
license: NVIDIA
srcversion: 1E2265D2AF1616FE7B5DC23
alias: pci:v000010DEd*sv*sd*bc06sc80i00*
alias: pci:v000010DEd*sv*sd*bc03sc02i00*
alias: pci:v000010DEd*sv*sd*bc03sc00i00*
depends: drm
retpoline: Y
name: nvidia
vermagic: 5.15.0-30-generic SMP mod_unload modversions
parm: NvSwitchRegDwords:NvSwitch regkey (charp)
parm: NvSwitchBlacklist:NvSwitchBlacklist=uuid[,uuid...] (charp)
parm: NVreg_ResmanDebugLevel:int
parm: NVreg_RmLogonRC:int
parm: NVreg_ModifyDeviceFiles:int
parm: NVreg_DeviceFileUID:int
parm: NVreg_DeviceFileGID:int
parm: NVreg_DeviceFileMode:int
parm: NVreg_InitializeSystemMemoryAllocations:int
parm: NVreg_UsePageAttributeTable:int
parm: NVreg_RegisterForACPIEvents:int
parm: NVreg_EnablePCIeGen3:int
parm: NVreg_EnableMSI:int
parm: NVreg_TCEBypassMode:int
parm: NVreg_EnableStreamMemOPs:int
parm: NVreg_RestrictProfilingToAdminUsers:int
parm: NVreg_PreserveVideoMemoryAllocations:int
parm: NVreg_EnableS0ixPowerManagement:int
parm: NVreg_S0ixPowerManagementVideoMemoryThreshold:int
parm: NVreg_DynamicPowerManagement:int
parm: NVreg_DynamicPowerManagementVideoMemoryThreshold:int
parm: NVreg_EnableGpuFirmware:int
parm: NVreg_EnableUserNUMAManagement:int
parm: NVreg_MemoryPoolSize:int
parm: NVreg_KMallocHeapMaxSize:int
parm: NVreg_VMallocHeapMaxSize:int
parm: NVreg_IgnoreMMIOCheck:int
parm: NVreg_NvLinkDisable:int
parm: NVreg_EnablePCIERelaxedOrderingMode:int
parm: NVreg_RegisterPCIDriver:int
parm: NVreg_EnableDbgBreakpoint:int
parm: NVreg_RegistryDwords:charp
parm: NVreg_RegistryDwordsPerDevice:charp
parm: NVreg_RmMsg:charp
parm: NVreg_GpuBlacklist:charp
parm: NVreg_TemporaryFilePath:charp
parm: NVreg_ExcludedGpus:charp
parm: NVreg_DmaRemapPeerMmio:int
parm: rm_firmware_active:charp
+ apt list --installed
+ grep nvidia
libnvidia-cfg1-510/jammy-updates,jammy-security,now 510.73.05-0ubuntu0.22.04.1 amd64 [installed,automatic]
libnvidia-common-510/jammy-updates,jammy-security,now 510.73.05-0ubuntu0.22.04.1 all [installed,automatic]
libnvidia-compute-495/jammy-updates,jammy-security,now 510.73.05-0ubuntu0.22.04.1 amd64 [installed,automatic]
libnvidia-compute-510/jammy-updates,jammy-security,now 510.73.05-0ubuntu0.22.04.1 amd64 [installed,automatic]
libnvidia-decode-510/jammy-updates,jammy-security,now 510.73.05-0ubuntu0.22.04.1 amd64 [installed,automatic]
libnvidia-egl-wayland1/jammy,now 1:1.1.9-1.1 amd64 [installed,automatic]
libnvidia-encode-510/jammy-updates,jammy-security,now 510.73.05-0ubuntu0.22.04.1 amd64 [installed,automatic]
libnvidia-extra-510/jammy-updates,jammy-security,now 510.73.05-0ubuntu0.22.04.1 amd64 [installed,automatic]
libnvidia-fbc1-510/jammy-updates,jammy-security,now 510.73.05-0ubuntu0.22.04.1 amd64 [installed,automatic]
libnvidia-gl-510/jammy-updates,jammy-security,now 510.73.05-0ubuntu0.22.04.1 amd64 [installed,automatic]
libnvidia-ml-dev/jammy,now 11.5.50~11.5.1-1ubuntu1 amd64 [installed,automatic]
nvidia-compute-utils-510/jammy-updates,jammy-security,now 510.73.05-0ubuntu0.22.04.1 amd64 [installed,automatic]
nvidia-cuda-dev/jammy,now 11.5.1-1ubuntu1 amd64 [installed,automatic]
nvidia-cuda-toolkit/jammy,now 11.5.1-1ubuntu1 amd64 [installed]
nvidia-cudnn/jammy,now 8.2.4.15~cuda11.4 amd64 [installed]
nvidia-dkms-510/jammy-updates,jammy-security,now 510.73.05-0ubuntu0.22.04.1 amd64 [installed,automatic]
nvidia-driver-510/jammy-updates,jammy-security,now 510.73.05-0ubuntu0.22.04.1 amd64 [installed]
nvidia-kernel-common-510/jammy-updates,jammy-security,now 510.73.05-0ubuntu0.22.04.1 amd64 [installed,automatic]
nvidia-kernel-source-510/jammy-updates,jammy-security,now 510.73.05-0ubuntu0.22.04.1 amd64 [installed,automatic]
nvidia-opencl-dev/jammy,now 11.5.1-1ubuntu1 amd64 [installed,automatic]
nvidia-profiler/jammy,now 11.5.114~11.5.1-1ubuntu1 amd64 [installed,automatic]
nvidia-utils-510/jammy-updates,jammy-security,now 510.73.05-0ubuntu0.22.04.1 amd64 [installed,automatic]
xserver-xorg-video-nvidia-510/jammy-updates,jammy-security,now 510.73.05-0ubuntu0.22.04.1 amd64 [installed,automatic]
+ nvidia-smi
Wed May 18 06:29:10 2022
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 510.73.05 Driver Version: 510.73.05 CUDA Version: 11.6 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA RTX A6000 Off | 00000000:01:00.0 Off | Off |
| 30% 22C P8 16W / 300W | 1MiB / 49140MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 1 NVIDIA RTX A6000 Off | 00000000:41:00.0 Off | Off |
| 30% 23C P8 23W / 300W | 1MiB / 49140MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 2 NVIDIA RTX A6000 Off | 00000000:81:00.0 Off | Off |
| 30% 25C P8 22W / 300W | 1MiB / 49140MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 3 NVIDIA RTX A6000 Off | 00000000:C1:00.0 Off | Off |
| 30% 24C P8 16W / 300W | 1MiB / 49140MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
======================== CUDA Toolkit ========================
libcuda.so.1 -> libcuda.so.510.73.05
libcudart.so.11.0 -> libcudart.so.11.5.117
libicudata.so.70 -> libicudata.so.70.1
======================== python ========================
+ python -c import sys; print(sys.version); print(sys.path)
3.10.4 (main, Apr 2 2022, 09:04:19) [GCC 11.2.0]
['', '/usr/lib/python310.zip', '/usr/lib/python3.10', '/usr/lib/python3.10/lib-dynload', '/usr/local/lib/python3.10/dist-packages', '/usr/lib/python3/dist-packages']
======================== Tensorflow ========================
+ python -c import tensorflow; print(tensorflow.__version__)
2.9.0
Loaded cuda toolkit:
/lib/x86_64-linux-gnu/libcudart.so.11.0
/lib/x86_64-linux-gnu/libcuda.so.1
/lib/x86_64-linux-gnu/libcufft.so.10
/lib/x86_64-linux-gnu/libcurand.so.10
/lib/x86_64-linux-gnu/libcusolver.so.11
/lib/x86_64-linux-gnu/libcublas.so.11
/lib/x86_64-linux-gnu/libcublasLt.so.11
/lib/x86_64-linux-gnu/libcusparse.so.11
/lib/x86_64-linux-gnu/libcudnn.so.8
2022-05-18 06:29:14.938165: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:975] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-05-18 06:29:14.938506: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:975] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-05-18 06:29:14.938794: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:975] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-05-18 06:29:14.939082: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:975] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-05-18 06:29:14.973280: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:975] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-05-18 06:29:14.994256: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:975] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-05-18 06:29:14.994898: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:975] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-05-18 06:29:14.995454: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:975] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-05-18 06:29:14.996001: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:975] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-05-18 06:29:14.999064: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:975] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-05-18 06:29:15.000182: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:975] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-05-18 06:29:15.000461: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:975] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
Detected GPUs: 4
2022-05-18 06:29:16.525022: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:975] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-05-18 06:29:16.525362: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:975] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-05-18 06:29:16.525648: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:975] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-05-18 06:29:16.525931: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:975] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-05-18 06:29:16.560336: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:975] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-05-18 06:29:16.560681: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:975] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-05-18 06:29:16.560964: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:975] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-05-18 06:29:16.561247: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:975] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-05-18 06:29:16.561525: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:975] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-05-18 06:29:16.561798: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:975] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-05-18 06:29:16.562070: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:975] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-05-18 06:29:16.562342: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:975] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-05-18 06:29:16.573495: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2022-05-18 06:29:16.984221: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:975] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-05-18 06:29:16.984542: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:975] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-05-18 06:29:16.984816: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:975] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-05-18 06:29:16.985088: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:975] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-05-18 06:29:16.985364: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:975] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-05-18 06:29:16.985628: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:975] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-05-18 06:29:16.985890: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:975] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-05-18 06:29:16.986153: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:975] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-05-18 06:29:16.986416: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:975] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-05-18 06:29:16.986679: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:975] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-05-18 06:29:16.986945: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:975] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-05-18 06:29:16.987207: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:975] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-05-18 06:29:18.404041: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:975] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-05-18 06:29:18.404415: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:975] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-05-18 06:29:18.404712: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:975] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-05-18 06:29:18.405001: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:975] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-05-18 06:29:18.405275: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:975] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-05-18 06:29:18.405553: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:975] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-05-18 06:29:18.405838: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:975] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-05-18 06:29:18.406104: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:975] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-05-18 06:29:18.406373: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:975] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-05-18 06:29:18.406651: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1532] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 46720 MB memory: -> device: 0, name: NVIDIA RTX A6000, pci bus id: 0000:01:00.0, compute capability: 8.6
2022-05-18 06:29:18.419618: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:975] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-05-18 06:29:18.419961: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1532] Created device /job:localhost/replica:0/task:0/device:GPU:1 with 46720 MB memory: -> device: 1, name: NVIDIA RTX A6000, pci bus id: 0000:41:00.0, compute capability: 8.6
2022-05-18 06:29:18.420291: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:975] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-05-18 06:29:18.420552: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1532] Created device /job:localhost/replica:0/task:0/device:GPU:2 with 46720 MB memory: -> device: 2, name: NVIDIA RTX A6000, pci bus id: 0000:81:00.0, compute capability: 8.6
2022-05-18 06:29:18.420848: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:975] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-05-18 06:29:18.421108: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1532] Created device /job:localhost/replica:0/task:0/device:GPU:3 with 46720 MB memory: -> device: 3, name: NVIDIA RTX A6000, pci bus id: 0000:c1:00.0, compute capability: 8.6
tf.Tensor(
[[ 51.6 -98.3 -91.6 ... 75.94 -47.38 89.25]
[ -48.53 -110.56 -34.03 ... 9.25 17. 152.6 ]
[ -25.05 106.44 -33.44 ... 127.25 131.8 -222.1 ]
...
[ -53.62 -10.4 26.03 ... -184.2 -20.52 94.1 ]
[ -35.75 -57.22 63.2 ... 148. 22.2 77.56]
[ -48.38 139.9 157.4 ... -48.9 -85.5 -194.4 ]], shape=(30000, 20000), dtype=float16)
device: /job:localhost/replica:0/task:0/device:GPU:0
We are PID = 57887
Wed May 18 06:29:20 2022
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 510.73.05 Driver Version: 510.73.05 CUDA Version: 11.6 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA RTX A6000 Off | 00000000:01:00.0 Off | Off |
| 30% 25C P2 92W / 300W | 47502MiB / 49140MiB | 14% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 1 NVIDIA RTX A6000 Off | 00000000:41:00.0 Off | Off |
| 30% 25C P2 68W / 300W | 428MiB / 49140MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 2 NVIDIA RTX A6000 Off | 00000000:81:00.0 Off | Off |
| 30% 27C P2 69W / 300W | 428MiB / 49140MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 3 NVIDIA RTX A6000 Off | 00000000:C1:00.0 Off | Off |
| 30% 26C P2 65W / 300W | 428MiB / 49140MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 57887 C python 47499MiB |
| 1 N/A N/A 57887 C python 425MiB |
| 2 N/A N/A 57887 C python 425MiB |
| 3 N/A N/A 57887 C python 425MiB |
+-----------------------------------------------------------------------------+
4.49user 8.31system 0:06.54elapsed 195%CPU (0avgtext+0avgdata 5198356maxresident)k
707424inputs+40outputs (3318major+1198440minor)pagefaults 0swaps
======================== Torch ========================
+ python -c import torch; print(torch.__version__)
1.11.0+cu113
+ python -c import torch; print(torch.cuda.is_available())
True
Loaded cuda toolkit:
/lib/x86_64-linux-gnu/libcuda.so
/usr/local/lib/python3.10/dist-packages/torch/lib/libcudart-a7b20f20.so.11.0
Detected GPUs: 4
tensor([[ 5.1328, -104.2500, -3.1445, ..., -115.8125, 25.5625,
-161.5000],
[ 58.8750, 33.5000, 105.1250, ..., 45.2188, -25.1250,
64.2500],
[ 17.9062, 92.9375, 38.1562, ..., 14.0312, 30.7812,
-110.7500],
...,
[ 14.7656, 110.3750, 14.0781, ..., 106.1875, -151.0000,
-65.3750],
[ 150.7500, -80.3750, -27.6719, ..., -66.1250, -99.1875,
153.6250],
[ -13.2422, 7.9688, -27.8906, ..., 103.1250, 29.6094,
77.6875]], device='cuda:0', dtype=torch.float16)
device: cuda:0
We are PID = 58390
Wed May 18 06:29:28 2022
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 510.73.05 Driver Version: 510.73.05 CUDA Version: 11.6 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA RTX A6000 Off | 00000000:01:00.0 Off | Off |
| 30% 29C P2 82W / 300W | 6436MiB / 49140MiB | 37% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 1 NVIDIA RTX A6000 Off | 00000000:41:00.0 Off | Off |
| 30% 24C P8 23W / 300W | 3MiB / 49140MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 2 NVIDIA RTX A6000 Off | 00000000:81:00.0 Off | Off |
| 30% 25C P8 22W / 300W | 3MiB / 49140MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 3 NVIDIA RTX A6000 Off | 00000000:C1:00.0 Off | Off |
| 30% 25C P8 17W / 300W | 3MiB / 49140MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 58390 C python 6433MiB |
+-----------------------------------------------------------------------------+
4.11user 7.71system 0:04.89elapsed 241%CPU (0avgtext+0avgdata 4846888maxresident)k
0inputs+0outputs (0major+1111789minor)pagefaults 0swaps
To get your software onto these servers, download it with git clone.
GPU-Agnostic code#
For the benefit of being able to test code out locally, without the GPU servers, it’s helpful to write device-agnostic code, code that falls back to running on slower CPU emulation if GPUs are not available.
For pytorch, this looks like this
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
...
# to make tensors
X = torch.empty((8, 42), device=device)
# to make neural networks
model = Network(...).to(device=device)
Installing torch-dependent packages#
When it comes to installing python packages, PyTorch is its own beast. You might encounter issues when trying to install recent versions of torch on the GPU clusters, or packages that depend on it.
What you should know is that your graphics card has a small program called a NVIDIA GPU driver. For all intents and purposes, the version of this driver is fixed. In parallel, PyTorch is a python wrapper over C/C++ code, so it contains 2 parts: the python code, and the lower-level code, including CUDA libraries. CUDA and your NVIDIA gpu driver need compatible versions. This means that the NVIDIA GPU driver version sets a maximum version for CUDA, which in turn puts a maximum version on the pytorch version that you can install. This is because when you install torch with pip, it ships with its own version of the required CUDA/cuDNN and runtime libraries. (see the compatibility matrix here).
For example, let’s look at romane and find out the maximum torch version it supports. Using nvidia-smi gives us the following information:
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.288.01 Driver Version: 535.288.01 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
Here, we can see that the NVIDIA GPU driver version is 535.288.01. For convenience, nvidia-smi also tells you the maximum CUDA version compatible with this driver: in our case, version 12.2. In other words, you cannot install any torch version that doesn’t support CUDA 12.2. According to the compatibility matrix, this means that we currently cannot install any PyTorch version >= 2.8, since they dropped support for CUDA < 12.6 at that point.
Data#
As with the other stations, you should prefer getting data in via git-annex in the git data server, but you have the option of using duke (which is available to you at ~/duke/temp) or any other method (scp, curl, wget, etc).
Storage#
Long term, slow access (with backup)#
For projects and permanent storage: ~/duke. More information about duke can be found here.
Warning
Please, do not use space on duke while training your models. If you need more local space, post a request on computers.
Mid-term, rapid access (no backup)#
This corresponds to your home ~/. This is where you keep your software (conda envs, virtualenvs, etc.).
Short-term, very rapid access (no backup)#
This is where you run your experiments (eg: deep learning training). On rosenberg, go to ~/data_nvme_$USERor ~/data_extrassd_$USER. On bireli and romane , go to your home ~/ .
To keep track of your disk space, you can run df:
u108545@rosenberg:~$ # to see how much space is available on the spare disk
u108545@rosenberg:~$ df -h data_extrassd_u108545
Filesystem Size Used Avail Use% Mounted on
/dev/sdb1 440G 50G 368G 12% /mnt/extrassd
u108545@rosenberg:~$ # to measure how much space a tool takes
u108545@rosenberg:~$ du -hs data_extrassd_u108545/miniconda3/
18G data_extrassd_u108545/miniconda3/
Good Training Habits#
Instead of loading the whole dataset to memory:
Use HDF5Matrix: https://gist.github.com/jfsantos/e2ef822c744357a4ed16ec0c885100a3
Provide a python generator like in: keras-team/keras#107
And:
Store data as float32 rather than float64
Monitoring#
You can monitor what the system is doing with
htop # CPU processes
and
nvtop # GPU processes
You can see how hot it is running with
u918374@rosenberg:~$ sensors
coretemp-isa-0001
Adapter: ISA adapter
Package id 1: +30.0°C (high = +80.0°C, crit = +90.0°C)
Core 0: +25.0°C (high = +80.0°C, crit = +90.0°C)
Core 1: +25.0°C (high = +80.0°C, crit = +90.0°C)
You can also see all this information plotted over time for each machine at
https://monitor.neuro.polymtl.ca/host/bireli.neuro.polymtl.ca/
https://monitor.neuro.polymtl.ca/host/rosenberg.neuro.polymtl.ca/
https://monitor.neuro.polymtl.ca/host/romane.neuro.polymtl.ca/
Monitoring GPUs#
As above, you can see the computation amount, allocated RAM, temperature, fan speed of the GPUs on the command line with
nvidia-smi
or
nvtop
You can see the same information over time at
romaneGPU 0: https://monitor.neuro.polymtl.ca/host/romane.neuro.polymtl.ca/#menu_nvidia_smi_submenu_gpu0_RTX_A6000romaneGPU 1: https://monitor.neuro.polymtl.ca/host/romane.neuro.polymtl.ca/#menu_nvidia_smi_submenu_gpu1_RTX_A6000romaneGPU 2: https://monitor.neuro.polymtl.ca/host/romane.neuro.polymtl.ca/#menu_nvidia_smi_submenu_gpu2_RTX_A6000romaneGPU 3: https://monitor.neuro.polymtl.ca/host/romane.neuro.polymtl.ca/#menu_nvidia_smi_submenu_gpu3_RTX_A6000
Monitoring these metrics during training will help you make more efficient batch sizes and other optimizations.
Tensorboard#
This feature allows you to monitor various training and validation metrics across epochs. If training is happening on a remote station (typically the case), you need to run tensorboard on the remote station and establish an SSH tunnel to be able to see the TensorBoard on your local browser.
To do on the remote GPU cluster:
Source virtual environment
Open a terminal session:
screen # If there is already a SINGLE screen session, reopen it: screen -dr # if there are more than one screen sessions, see which ones are active: screen -ls # Then select the one you like: screen -r PID
Launch tensorboard:
export TMPDIR=/tmp/$USER mkdir -p $TMPDIR tensorboard --logdir PATH_TO_MODEL --port PORTNUMBER
with:
PATH_TO_MODEL: Is the path to the folder that contains the file*.tfevents.*PORTNUMBER: Pick one number that is different from the port number that other people might be using on the same station. Examples: 6008, 6009, etc.
Create an SSH tunnelling between your local station and the remote server.
Open a browser and go to: http://localhost:8080/.
SSH tunnelling#
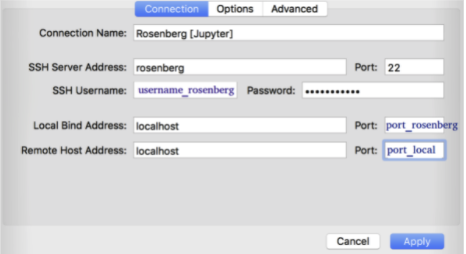
If you want to run a Jupyter notebook from a remote server, or monitor a model training using tensorboard, you will need to do an SSH tunnelling to be able to pass the display from the remote cluster to your local station.
Install secure pipes and configure it as follows: with port_rosenber as the “Port” of the screen session and port_local is a random number (see screenshot below):
ssh -N -f -L localhost:8080:localhost:PORTNUMBER username@CLUSTER.neuro.polymtl.ca
Once the SSH tunnel is established, open a browser and go to: http://localhost:8080/.
Warning
If you get the following error:
bind: Address already in use
channel_setup_fwd_listener_tcpip: cannot listen to port: 8080
Could not request local forwarding.
You need to kill whatever application is using that port:
lsof -ti:8080 | xargs kill -9
Reference: https://fizzylogic.nl/2017/11/06/edit-jupyter-notebooks-over-ssh/